XMLSplitter can be used to split XML documents based on the configured XPath. This component is useful when there are repeated elements in the documents that can be processed independently by subsequent components.
Configuration and Testing
Interaction Configurations
The following attributes can be configured in the Interaction Configuration panel as shown below.
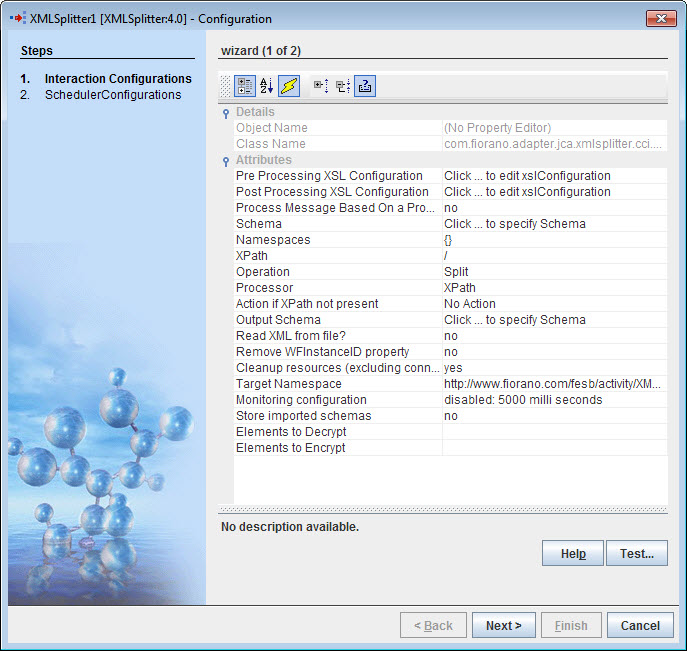
Figure 1: Interaction Configuration Properties
Attributes
Pre Processing XSL Configuration
Pre Processing XSL configuration can be used to transform request message before processing it. Click the small button against the property to configure the properties.
Post Processing XSL Configuration
Post Processing XSL configuration can be used to transform the response message before sending it to the output port.
Process Message Based on Property
The property helps components to skip certain messages from processing.
Schema
The XSD of the input XML message has to be specified here. The XSD can be provided using schema editor which pops up on clicking ellipsis button  against this property. If the schema has any namespaces, then they will be automatically populated in the Namespaces table shown in Figure 2.
against this property. If the schema has any namespaces, then they will be automatically populated in the Namespaces table shown in Figure 2.
Namespaces
Namespace prefixes that are used instead of the complete namespace in XPath expression can be specified by clicking the ellipsis button against this property which opens a Namespaces table as shown in Ffigure 2. The namespaces present in the input schema, if any, are automatically populated in the table. If the user wants to provide XPaths manually and use the namespaces which are not present in the schema provided, they can be added using the namespaces tab
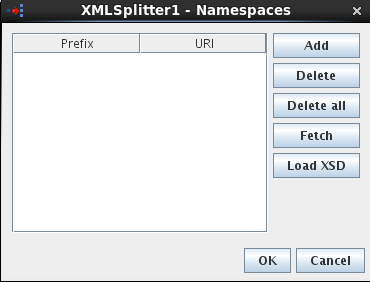
Figure 2: Namespace Table
- Prefix
The prefix with which a given namespace is identified. Prefix fsoa is reserved. - URI
The URI of the namespace.
Operations that can be performed in the namespace table are:
- Add
Namespaces present in the schema provided against property Schema are populated by default in the table. To use any namespaces that are not present in that schema, this option can be used. When the add button is clicked, a new namespace will be added with default prefix and URI. The columns are editable and thus an appropriate value can be specified in place of the default values. - Delete
Existing namespaces can be deleted from the table using this option. When namespaces are fetched from connected components or some XSD, there is a possibility that namespaces with the same URI are added with a different namespace prefix. In such cases, redundant namespaces can be deleted. This will not affect the schemas in which the namespaces are present. - Delete all
Deletes all the namespaces in the table. - Fetch
Fetches namespaces from the schemas present on ports of other components connected to XMLSplitter component. Thus it is advisable to configure the connected components completely before using this option. - Load XSD
Loads namespaces from the schema which is provided in the text editor opened when this button is clicked. This option can be used when there are XSDs whose namespaces are required for configuration. One schema must be loaded a time. The schemas are not stored in the component.
XPath
The XPath of the element based on which the split or group operation has to be performed is configured here. Click the ellipsis button to open XPath editor. Choose an element/attribute from the list displayed in the left side panel of XPath editor and drag it onto the easel on the right side. The configured XPath expression must always evaluate an element or an attribute. XPath expressions that evaluate to any other types are not valid.
Operation
The operation that has to be performed on the input XML message which is categorized as:
- Split
- Group
Split
Splits the input XML at XPath defined and sends out output XMLs. The number of output XMLs is equal to the number of times the element/attribute defined by the property XPath is present in the input message.
Processor
The Processor to be used for splitting. This property will be visible only when the Operation is 'Split' is selected.
- Xpath
Uses XPath Processor for splitting.
XSLT
Uses XSLT for splitting. When the 'Operation' is 'Group', XSLT processor will be used for processing, so this property will not be visible in that case.
Group
Splits the input XML at the element whose XPath is specified by the property XPath and then regroups the split XMLs which have the same value for that element into a single message. Thus the number of messages sent onto the output port depends on the number of unique values present in XML for the element whose XPath is specified by the property XPath.
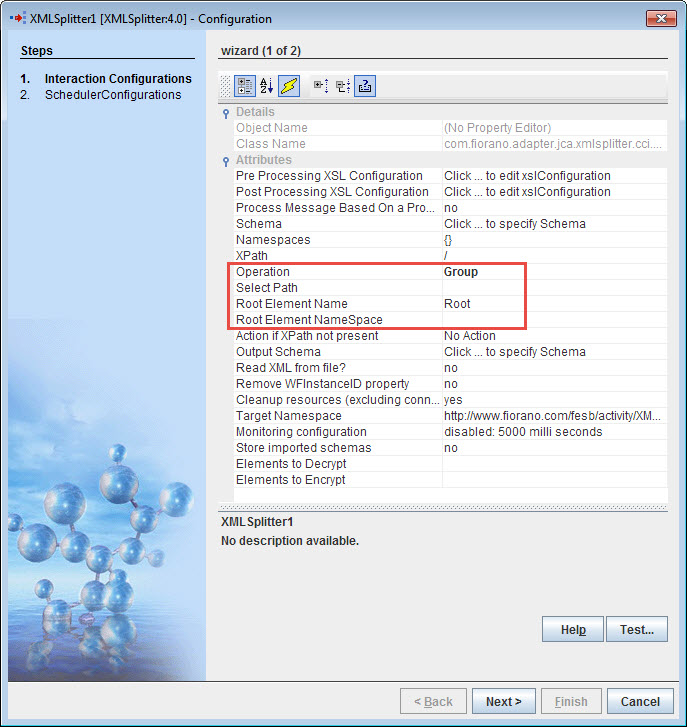
Figure 4: Properties under Group operation
Select Path
Specifies the path of the XML data element on which grouping is to be done.
Root Element Name
Root Element Name for the output XML(s). This property will be visible when the Operation is selected as Group.
Root Element NameSpace
Namespace for the root element in output XML(s). If the default value is selected, then the root element namespace will be the same as the target namespace of the input XSD provided. This property will be visible when the Operation is selected as Group.
Action if XPath not present
Action to be taken if the input message does not contain the configured XPath.
No Action
Component will ignore the message.
- Treat As Exception
Sends an Exception to Exception port.
- Send To Output Port
Sends the input message to the output port as it is.
Output Schema
Schema for the output message can be specified. The schema can be specified exclusively or can be generated with the help of input schema and XPath by clicking Get schema based on input and XPath button in the schema editor. This is not guaranteed to give a valid schema always. Please verify when using this feature.
Read XML From File?
The XML can be read directly from the specified file by setting this property as yes. 'XML File Directory' and 'XML File Name' properties are visible when this option is set to 'yes'.
XML File Directory
Directory of the input XML file.
XML File Name
Name of the input XML file which has to be split.
Remove WFInstanceID property
If set to 'yes', the Workflow Instance ID will be removed and after encountering the next workflowItem config, WorkFlow_Instance_ID will be added automatically with a new value, making split messages with unique IDs.
Cleanup resources (excluding connection) after each document
This closes all the resources except for the connection after every request. If less processing time is more important than less memory usage, then it is recommended to disable this property and vice versa.
For more details, refer to the respective section under in the Common Configurations page.
Target Namespace
Target Namespace for the request and response XML messages.
For more details, refer to the respective section under in the Common Configurations page.
Monitoring Configuration
Please refer to the Monitoring Configuration section in Common Configurations page.
Store imported schemas
Selecting "yes" stores imported schemas in Schema Repository.
Elements to Decrypt
Please refer Port Properties section in the Common Configurations page.
Elements to Encrypt
Please refer Port Properties section in the Common Configurations page.
Sample Input and Output
The configuration can be tested by clicking the Test button in the interaction Configuration panel.
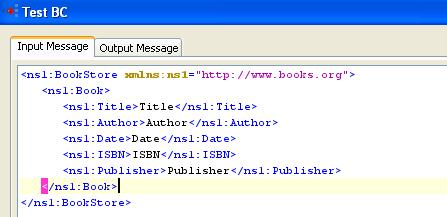
Figure 6: Sample Input Message

Figure 7: Response Generated for XPath /ns1:BookStore/ns1:Book/ns1:Author
Scheduler Configurations
Please refer Scheduler Configurations section in the Common Configurations page.
Functional Demonstration
Scenario 1
Splitting the input XML with respect to an element.
Configure the XMLSplitter as shown in the figure below.
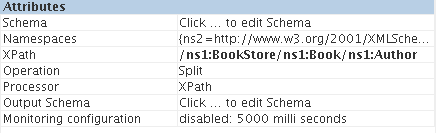
Figure 8: configuration for scenario 1
Use Feeder and Display components to send sample input and to check the response respectively. In the example given below, the Split element selected is Author.
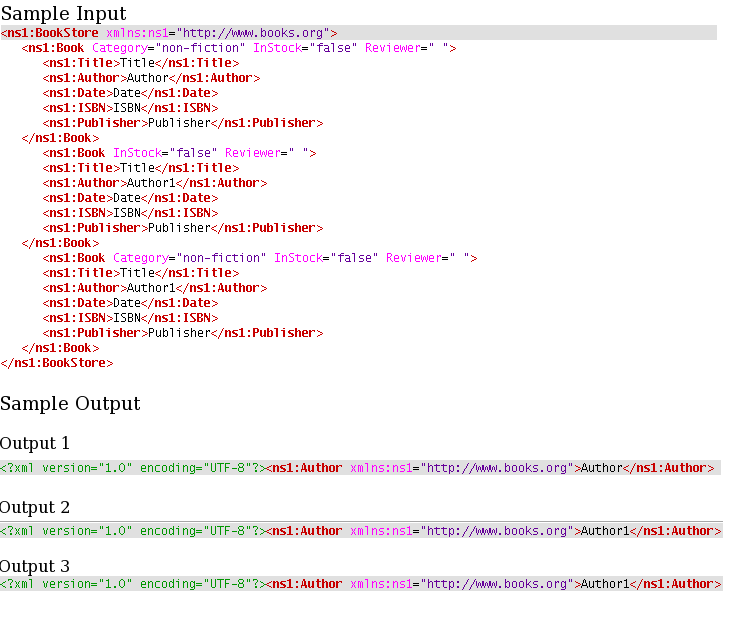
Figure 9: Scenario demonstration with sample input and output
Scenario 2
Grouping the Input XML based on the XPath provided.
Configure XMLSplitter as described in Configuration and Testing section. The configuration for this example is shown below. In the example given below, the Xpath element selected is /ns1:BookStore/ns1:Book/ns1:Title and Group is selected as /ns1:BookStore/ns1:Book.
This operation splits the XML by the path configured for the Group and accommodates all the messages having the same Xpath value into a single message under the value configured for the group. So, the number of messages depends upon the number of distinct values configured for XPath.
In this example, 'Title' is one of the children of 'Book'.
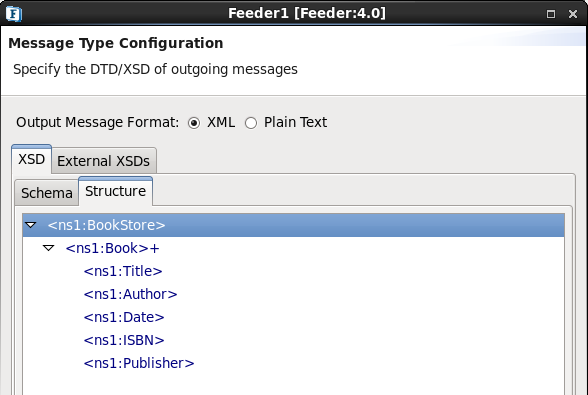
Figure 10: Schema Structure as per Scenario 2
Observe the two outputs shown in the figure below.
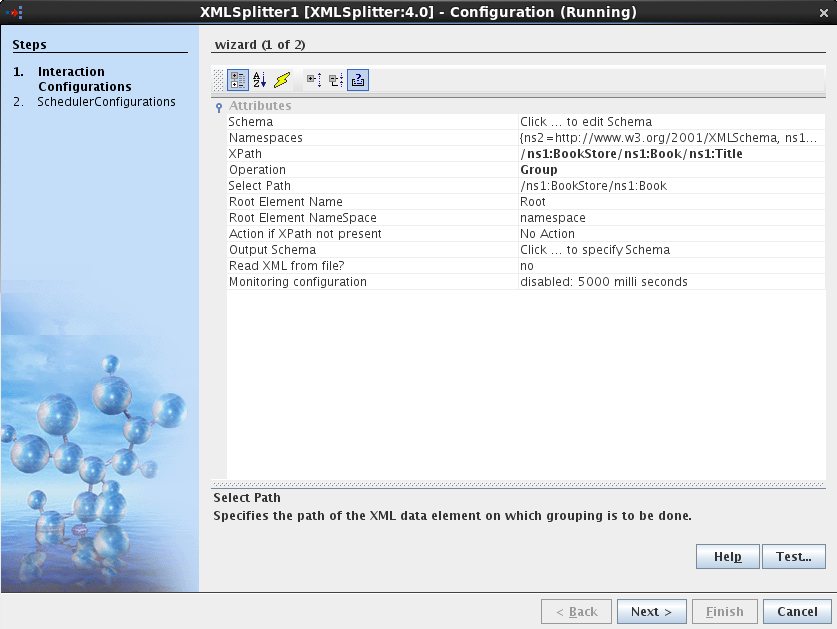
Figure 11: Configuration Properties panel
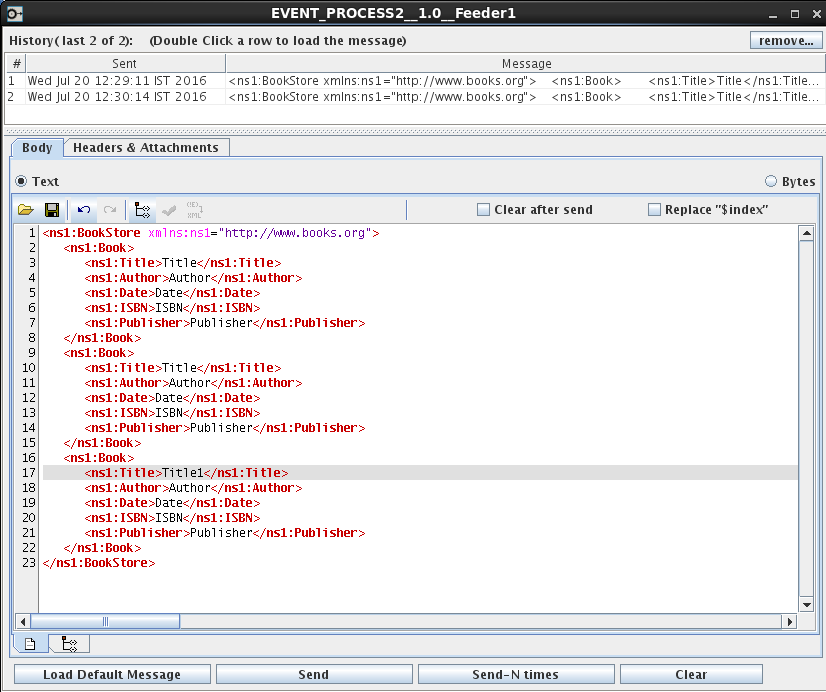
Figure 12: Sample input for Scenario 2
The following two messages appear in the output, as there are only 2 different values sent in the input for the 'Title' (Configured for Xpath) and they are grouped under 'Book' (configured for Group).

Figure 13: Output for Scenario 2
Use Case Scenario
In the Bond Trading sample Event Process, XML Splitter is used to split the Isin data into individual Isin elements.
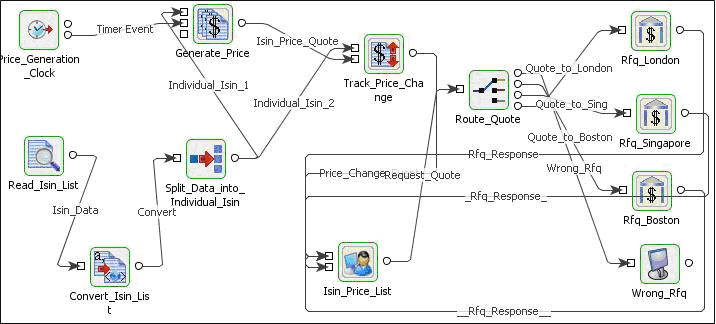
Figure 14: Sample use case scenario
The event process demonstrating this scenario is bundled with the installer.
Documentation of the scenario and instructions to run the flow can be found in the Help tab of flow present in the eStudio application.
Useful Tips
- The output schema can be computed from the input schema and the XPath used to split the XML document using the Get Schema based on Input and XPath
 button in the schema editor for property OutputSchema. This is not guaranteed to give a valid schema always. Please verify when using this feature.
button in the schema editor for property OutputSchema. This is not guaranteed to give a valid schema always. Please verify when using this feature. - Prefer XSLT for simple split paths and XPath for complex paths. All kinds of split paths may not be supported by XSLT.
- When component configuration sends multiple messages, messages contain the following JMS properties to identify first and last messages.
- First document: START_EVENT=true
- All documents: RECORD_INDEX=<index of output message>
- Last document: CLOSE_EVENT=true
- When the input XML does not contain the element specified at Xpath, splitting/grouping is not performed and there will be no output messages in this case.
- The output generated has the same instance id for all the split elements. This causes issues when document tracking, if you try to track both documents on the output of the splitter, you only get a single entry (due to the duplicate instance ID's).
- To have different Instance Ids for different documents, workflow items in the flow have to be set properly.
- The Instance ID is set at the first "Workflow Item" encountered in the event process, so if the 1st workflow item is set before OUT_PORT of XMLSplitter then there will be only one "Instance ID" for all split messages, however, all split messages can have different "Document ID". On the other hand, if the first "Workflow Item" is set at OUT_PORT of XMLSplitter each element will have a different "Instance ID".