KinesisProducer microservice is used to write data records to Amazon Kinesis Streams.
Configuration and Testing
Component Configurations
The following attributes can be configured in the Component Configuration panel as shown below.
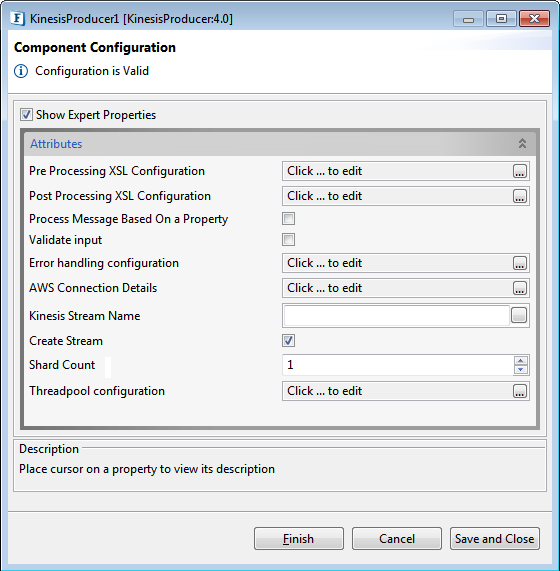
Figure 1: Component Configuration Properties
Pre Processing XSL Configuration
Pre Processing XSL configuration can be used to transform request message before processing it. Click the small button against the property to configure the properties.
Post Processing XSL Configuration
Post Processing XSL configuration can be used to transform response message before sending it to the output port.
Process Message Based on Property
The property helps components to skip certain messages from processing.
Validate Input
If this attribute is enabled, the service tries to validate the input received. If disabled, service will not validate the input. For more details, refer Validate Input section section under Interaction Configurations in Common Configurations page.
Error handling configuration
The remedial actions to be taken when a particular error occurs can be configured using this attribute.
Click the ellipsis button against this property to configure Error Handling properties for different types of Errors. By default, the options Log to error logs, Stop service and Send to error port are enabled.
Refer Error Handling section in Common Configurations for detailed information.
AWS Connection Details
Click the AWS Connection Details ellipsis  button to configure the properties.
button to configure the properties.
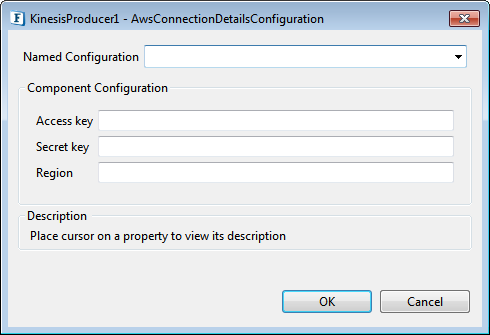
Figure 2: KinesisProducer connection configuration properties
Access key
Specify the Access Key id
Secret key
Specify the Secret Key
Region
The region of AWS Management console.
Kinesis Stream Name
Name of the Kinesis Stream to which the data records are written.
Create Stream
Enable this option to create a stream if it does not exist.
Shard Count
A shard is a uniquely identified group of data records in a stream. A stream is composed of one or more shards, each of which provides a fixed unit of capacity.
Specify the number of shards to be used.
Threadpool Configuration
This property is used when there is a need to process messages in parallel within the component, still maintaining the sequence from the external perspective.
Click the Threadpool Configuration ellipsis button to configure the Threadpool Configuration properties.
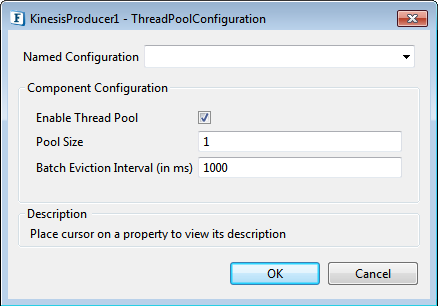
Figure 3: KinesisProducer Threadpool configuration properties
Enable Thread Pool
Enable this option to configure the properties that appear as below.
Pool Size
Number of requests to be processed in parallel within the component. Default value is '1'.
Batch Eviction Interval (in ms)
Time in milliseconds after which the threads are evicted in case of inactivity. New threads are created in place of evicted threads when new requests are received. Default value is '1000'.
Functional Demonstration
The following flow demonstrates a flow of Kinesis Producer, which inputs the Data with provided partition key to the stream.
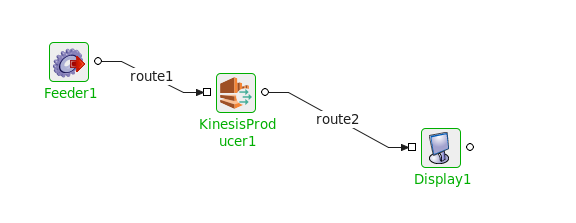
Figure 4: KinesisProducer sample flow
Input Message
The Input message consists of the following elements
Data
Data to be sent to the Kinesis stream.
Partition key
A partition key is used to group data by shard within a stream. The Streams service segregates the data records belonging to a stream into multiple shards using the partition key associated with each data record to determine which shard a given data record belongs to.
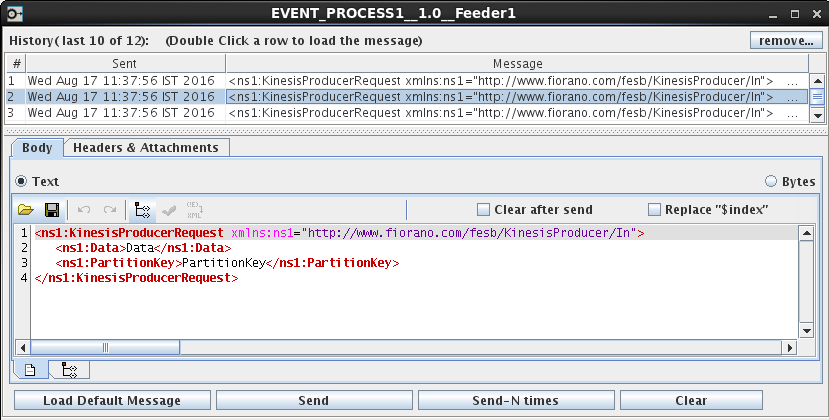
Figure 5: Sending data via Feeder Input
Output Message
The output message consists of following elements.
Partition key
A partition key is used to group data by shard within a stream. The Streams service segregates the data records belonging to a stream into multiple shards using the partition key associated with each data record to determine which shard a given data record belongs to.
ShardID
The ID of the Shard the record is written to.
SequenceNumber
Sequence number defines the sequence of records in a particular shard
Each data record has a unique sequence number.
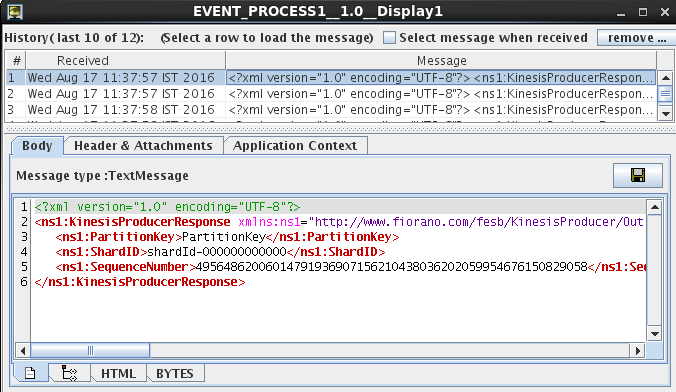
Figure 5: Output displayed in the Display window